

Amir is the Phase Lead for Instrument at MUO. He is a PharmD scholar who loves having a look at numbers and spreadsheets.
Impressed by way of his father’s spare time activities, Amir advanced a knack for DIY tasks and constructed his first quadcopter in highschool. At 18, he started writing about three-D printing, and now contributes to MUO the place he writes and edits productiveness gear, AI and LLMs, spreadsheets, self-hosting, DIY tasks, and much more.
Amir additionally enjoys growing song, despite the fact that its categorization as such stays open to interpretation. As well as to his instructional interests, Amir is an avid gamer, automotive fanatic, and proud proprietor of a 1993 Mitsubishi Galant.
Local LLMs are implausible, and they preserve getting higher at a staggering tempo. I have non-negotiable reasons for preferring a local setup over relying on cloud giants like Claude or ChatGPT. As a result of that, I have been relentlessly attempting to combine native fashions into my precise, day-to-day workflow.
However as somebody who has attempted will inform you, the DIY course comes with distinct caveats and drawbacks.
The completely largest hurdle is the context window. To get well responses from an LLM, we’d like to give it extra context. However context is pricey. And as quickly because the context window begins to refill, the model begins to go to pot in each pace and high quality. So what are we intended to do?
The issue, I spotted, used to be no longer the LLM itself. The issue used to be that I used to be the use of the LLM for a task it used to be by no means supposed to do. And the repair used to be a tiny model I had totally unnoticed.
LLMs and the issue of context
It in reality is pricey

Part of our revel in with a language model comes down to what we installed entrance of it. If we give it a imprecise, skinny advised, you get a imprecise, skinny resolution. For higher responses, we’d like to give the LLM extra context.
The issue is that context is pricey. On a cloud model, extra context manner extra tokens, and extra tokens imply upper prices. In the neighborhood, it manner slower inference, as a result of each and every unmarried token in that context window has to be processed throughout era. For a neighborhood model particularly, this issues much more.
We’re already running with smaller machines and tighter constraints. Dumping complete paperwork into the context window each and every time you ask a query actively degrades the revel in. The model spends an excessive amount of of its power dragging round data, slightly than in reality reasoning with the portions that subject.
An embedding model is what let me repair that.
Embedding fashions
The unsung warriors of native LLMs
|
|
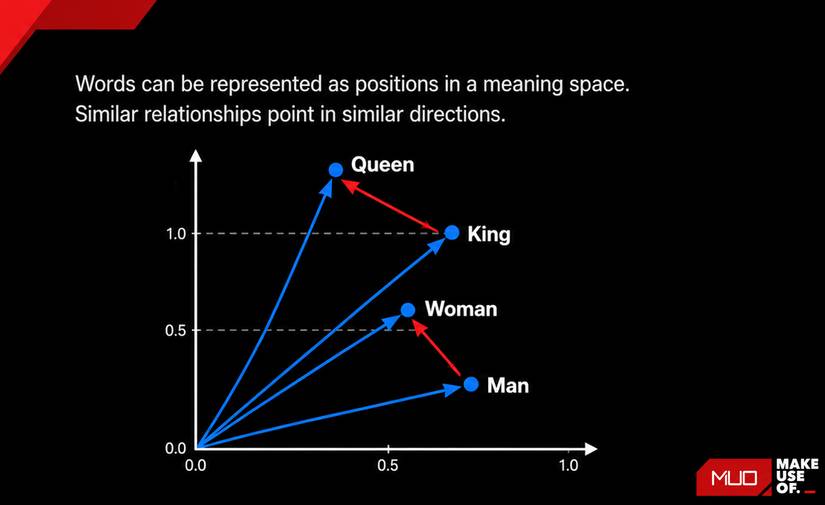
This 2D view is only for representation. Actual embedding use many extra dimensions. |
The tiny model in query is an embedding model. Embedding fashions come in several sizes, however when put next to an LLM, they in reality are tiny. What an embedding model does is relatively summary, however I’ll do my easiest to provide an explanation for it.
An embedding model takes a work of textual content and converts it into a protracted listing of numbers. That listing is known as a vector, and it represents the that means of the textual content in mathematical area.
Two sentences that imply more or less the similar factor will produce vectors which might be shut in combination in that area. Two sentences that experience not anything to do with every different will probably be a ways aside.
This isn’t key phrase seek. The model does no longer care about actual key phrases in the similar means an ordinary seek field does. The embedding model understands semantic similarity.
If my rationalization and chart nonetheless did not do the trick, the YouTube brief beneath does the subject justice:
This development is known as RAG
RAG or Retrieval-Augmented Technology. The speculation is that as an alternative of baking your whole wisdom into the model itself, you stay it exterior, in a vector database, and retrieve handiest the related items nowadays you want them. The model’s task remains inquisitive about what it is just right at, which is producing a reaction.
First, an embedding processes your paperwork and converts every chew of textual content right into a vector. The ones vectors get saved in a devoted database (one thing like ChromaDB or Qdrant, either one of which run in the neighborhood to your system). This phase occurs as soon as.
Then, while you ask a query, the similar embedding model converts your question right into a vector too. The database runs a similarity seek and surfaces the chunks which might be closest in that means to what you requested. The ones chunks get handed to your LLM as context, along the unique query. The LLM handles the translation.
You’ve already benefited from this with out understanding. NotebookLM, Google’s research assistant, lets you drop thousands and thousands of words worth of sources into it for free. Is Google being strangely beneficiant with tokens?
No. That is embedding at paintings. It does not load your whole resources into the model on each and every question — it retrieves handiest what is related, cost effectively and straight away. The heavy lifting is offloaded to a procedure that prices nearly not anything to run.
Yours will also be very other, after all
|
|
Even supposing the setup works superbly, I do not need gorgeous screenshots to proportion because the output is solely an LLM reaction. |
Probably the most instant use case for a neighborhood LLM is your paperwork. For this, you’ll already demo the speculation in LM Studio, the preferred native LLM interface, with out a lot setup. LM Studio already ships with RAG baked in. That’s what the “embedding model up to date” toasts are about. In a brand new dialog together with your LLM, make sure that the RAG MCP is enabled, then add your paperwork. This is mainly it.
I sought after to constantly embed my Obsidian magazine entries, and this wasn’t chronic sufficient. For anything else extra everlasting, I like to recommend downloading an embedding model and internet hosting it along your LLM.
I use mxbai-embed-large-v1. An alternative choice is embeddinggemma-300m. Those are all extensive embedding fashions, however in sensible phrases, they absorb round 500MB of garage, and you’ll simply absolutely offload them to your GPU.
From right here, you have got choices. You’ll be able to use a pre-built app like OpenNotebook, which is basically a self-hosted NotebookLM clone, then level it on the LLM and embedding model you have got hosted. From there, you add your resources and use them within that app.
However once more, that calls for you to use OpenNotebook for the queries. I sought after extra flexibility.
So I arrange Qdrant because the vector database. It is extremely simple to arrange (thanks, Docker). Then, with a easy Python script, I will be able to have interaction with the embedding model and have it embed my information into the Qdrant database.
From there, I packed all of this into an MCP server, attached it to OpenClaw, and that used to be it. Now my agent can pull in related context with out burning via the whole lot. The good thing about an MCP server is that I will be able to plug it into nearly each and every different AI interface. Claude Code, Codex, and Antigravity all reinforce MCP servers.
Embedding is going means additional than simply “paperwork”
Use it for a chronic revel in
Markdown is the programming language of 2026. Massive language fashions take language as enter and then output language. Phrases are the programming language.
You probably have your individual AI agent, then an embedding model is important for chronic reminiscence. The opposite is sending each and every unmarried previous dialog as context in each and every new message. Clearly, that’s not possible at scale. It’s sluggish, it breaks token limits, and it makes the revel in worse. The embedding model is what permits the machine to be selective.
So the workflow will also be one thing like this: OpenClaw, or no matter agent you might be the use of, assists in keeping a report of conversations in Markdown. The ones information are embedded right into a vector database with an embedding model. On every occasion OpenClaw wishes to get entry to previous chats, its reminiscence, it could possibly question the vector database and get precisely what it wishes to take into account.
It’s nearly precisely how human reminiscence works. You do not get started a dialog together with your easiest good friend by way of introducing your self, telling them your title, and then list the whole lot you have got ever finished in combination (except you are making some degree!) No. The ones occasions are already there. They’re recalled when wanted.
I have used this for my magazine, and it is been a milestone growth in getting a local LLM to work with my Obsidian vault. No matter your use case is, I counsel you put up the pipeline. As soon as the LLM stops wearing each and every piece of context on its again and begins retrieving handiest what issues, the entire revel in shifts.